
Motivation:
When we talk about efficiency of an algorithm, we generally refer to the resources (time, space etc.) that the algorithm will consume for a given input. Especially, we usually are interested in how an algorithm will behave (as in how much time or space will be consumed) for voluminous input size.
A solution to predict the behaviour (say running time) is to come up with a function ƒ(n) that emulates the the time taken by the algorithm for a given input of size n; it can be done by implementing the algorithm, executing it for different input-sizes while recording the processing-time taken, and plotting a graph (input-size on x-axis and running-time on y axis). A clear disadvantage in this approach is the dependence on too many external factors — programming language used for implementation; computing machine, its architecture and operating system etc. used for execution; how many other programs are running on the same machine while execution; and so on. We would like to abstract the analysis of the algorithm from all these external factors that do not have anything to do with the algorithm itself. Not only that, while comparing the performance of two algorithms so as to choose the better of the two, we do not want interference from any other external factor. Mathematics provides the abstraction technique required while analysing efficiency of an algorithm, namely — Asymptotic Notation.
Asymptotic Notation:
Let us assume that, for an input of size n, the running time of an algorithm is represented by a function T(n). T(n) can be any function but for easy analysis we would like to have running-time expressed in terms of ‘simpler’ functions (whose behaviour we already know) that more or less approximate T(n) to give some sort of ‘guarantees’. Asymptotic notation provides us the bounds of T(n) when n grows towards large value (tends to infinity).
Mathematical view –
Consider the following graph to grasp the mathematical meaning of the asymptotic notation.

Assuming that f(n) is a simple function ‘known’ to us (e.g. linear, polynomial, exponential, logarithmic etc.) and c is a constant, we can say that for any value of n after n0, T(n) will never be greater than c.f(n). Simply we can say that T(n) is order of f(n) and write it as follows:
T(n) = O(f(n))
Thus, the O (pronounced big-oh) notation is the formal way of expressing the upper bound of an algorithm’s running time. More formally, for two non-negative functions, T(n) and f(n), if there exists an integer n0 and a constant c > 0 such that for all integers n > n0, T(n) ≤ cf(n), then T(n) is Big O of f(n). This is denoted as T(n) = O(f(n)).
Analogously, we can express the lower bound in terms of big-omega notation.

Here, T(n) and g(n) two non-negative functions and there exists an integer n0 and a constant d > 0 such that for all integers n > n0, T(n) ≥ d.g(n), therefore T(n) = Ω(g(n)).
There is another notation, called theta notation: For non-negative functions, T(n) and f(n), T(n) is theta of f(n) if and only if T(n) = O(f(n)) and T(n) = Ω(f(n)). This is denoted as T(n) = Θ(f(n)). Simply, it implies that T(n) is upper-bounded as well as lower-bounded by the same function.
Note that we should use as tight bound as possible.
Algorithmic View –
Consider an algorithm — linear search — that finds a number in a given array of numbers by looking at each number starting from the first until it finds the number or the array ends. What is the worst case here (i.e. when the algorithm runs longest)? Answer is when the number we are trying to find is the last element of array or it not there at all. Similarly, the best case scenario (i.e. algorithm runs for the shortest time) is when the number is the first element of the array.
The O notation represents the longest running-time of an algorithm for a given input size. In a way, it represents the time taken in the worst case scenarios (that force the algorithm to run the longest). The Ω notation, on the other hand, is to express best case scenarios. For the above mentioned algorithm, assuming that looking at (comparing with) one element of array takes constant time, running time T(n) is O(n) [it will stop after checking n numbers] and Ω(1) [it will stop after just constant number of operations].
If the algorithm had been designed such that it will go through all numbers of the array even after it has found the given number, then T(n) would have not only been O(n) but also Ω(n). In this case we would have said T(n) = Θ(n).
A more pedantic way is to see the bounds of the time taken by the algorithm on the worst case input and the best case input separately. In other words, specifying the O notation and Ω notation for each — the worst-case input and the best case input –separately. Of course, upper bound of the worst case and the lower bound of the best case will constitute the overall O notation and Ω notation of the algorithm, respectively. For example, in linear search:
1. The worst case (when the element is not present in the sequence):
upper-bound -> linear (T(n) =O(n))
lower- bound -> linear (T(n) =Ω(n))
Therefore, the worst case time is Θ(n).
2. The best case (when the element is the first in the sequence):
upper-bound -> constant (T(n) =O(1))
lower- bound -> constant (T(n) =Ω(1))
Therefore, the best case time is Θ(1).
But the algorithm, overall, is O(n) and Ω(1).
Calculating the O notation:
The mathematical definition is usually not used to calculate the big-oh notation of some function T(n). There are some simple rules to compute the O notation, given as follows:
- O(1) is same as some constant c.
- Multiplication of orders: O(f(n) × O(g(n)) = O(f(n) × g(n)):
Example – O(n) × O(log n) = O(n × log n) - Addition of orders: O(f(n) + O(g(n)) = O(f(n) + g(n)):
Example – O(log n) + O(log log n) = O(log n + log log n) - Ignore the constant terms in a product (i.e. the terms which do not depend on n):
For example, T(n) = 5 n2, then T(n) = O(n2). - Ignore the terms with lower growth-rate in a sum of several terms, keeping only the largest growing term:
T(n) = n3 + n2 + 6, then T(n) = O(n3) because n3 is larger growing then the other two terms.
The following table will give an idea of the growth-rate of the most common functions.
| f(n) | n=1 | n=10 | n=100 | n=1000 | n=1000000 | |
|---|---|---|---|---|---|---|
| constant | c | c | c | c | c | c |
| logarithmic | log n (base 10) | 0 | 1 | 2 | 3 | 6 |
| linear | n | 1 | 10 | 100 | 1000 | 1000000 |
| quadratic | n^2 | 1 | 100 | 10000 | 10^6 | 10^12 |
| polynomial (power 3) | n^3 | 1 | 1000 | 10^6 | 10^9 | 10^18 |
| exponential (base 10) | 10^n | 10 | 10^10 | 10^100 | 10^1000 | 10^1000000 |
The above table also provides a glimpse of efficiency of algorithms with various order-functions. The running-time comparison of different classes of the algorithms can be presented as the following relation (Please note that use of “<” symbol is wrong mathematically speaking as O(f(n)) represents a set, but it is used to give a ‘sense of time’ taken):
O(1) < O(log n) < O(n) < O(nc) < O(10n)
Alternatively, algorithms classes can be ranked in the following sequence (best to worst time-complexity): Constant-time, linear, quadratic, polynomial, exponential.
While calculating the asymptotic complexity of an algorithm, we aim to find the tightest possible bounds. Less formally, the bound is tight if there is an input that will make the algorithm run as long as has been depicted by the bound. For example, we can say that the linear search is O(n2) because T(n) < c.n2 (for some constant c). However, O(n2) is not the tight bound (as there is no input for which the algorithm will require time corresponding to n2). On the other hand, O(n) is the tight upper-bound because the algorithm takes O(n) time on the input when the element is not present in the sequence. Similarly, Ω(n) is the tight lower-bound of the linear search algorithm.
Note that Θ notation inherently signifies asymptotically tight bounds.
Examples:
Linear Search –
Consider the linear search algorithm given above to find the position of a number in an array (and returning NULL if the number is not in the array). We can write it in pseudo-code as
For i from 1 to n:
If element at position i has the desired value,
stop the search and return the location (i.e. i);
Return NULL;
Here, checking whether the element at position i is same as the number is a simple operation, that doesn’t depend on the input. We assume that it can be done in constant time in a machine. Therefore, comparison step takes O(1) time. In the worst case we will have to do comparisons for each i from 1 to n; thus, the total running time will be
T(n) = O(1) + O(1) + O(1) + …… n times
T(n) = n × O(1) = O(n)
Maximum Pair-sum –
We have been given an array of numbers (say positive), we need to report the maximum sum of a pair of any two numbers in this array. One possible (rather naive) algorithm can be to find sum of all pairs of numbers, keeping track of the maximum sum found until now, so that in the end we have the overall maximum pair-sum.
Initialise SUM to 0; // variable for keeping the maximum sum
Initialise tempSUM to 0; // variable for keeping sum of the current pair
For each i from 1 to n-1:
For each j from i+1 to n:
Store sum of numbers at position i and position j in tempSUM;
If tempSUM > SUM
SUM = tempSUM;
Return SUM;
Here, both of the initialisation steps take constant time. Finding sum of two numbers, storing in a variable, comparing two variable — all these steps are constant time (say c).
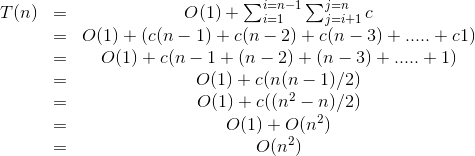
Thus, the algorithm is quadratic time.
Binary Search –
Now, we have to search a number in a given array of numbers but the array is sorted. We can make use of this information (instead of going for linear search). We can design the solution as follows:
If array is empty
Return NULL;
Else
Go to middle position;
If element at middle position is same as the desired number
Return middle;
Else If element at middle position > the desired number
Search in the Left half of the array;
Else
Search in the Right half of the array;
This is a recursive solution where the size of the array gets halved in each recursive call. Let’s first calculate how many recursive calls will be there:
If the algorithm makes k calls then (n/2k)= 1 => n =2k => k = log2 n.
As calculating middle position and comparison is constant time and there are k (=log2n) number of calls, we have
T(n) = k × O(1) = O(log n) × O(1) = O(log n)
Epilogue:
Please pardon the verbosity, oversimplification, and baby-steps. This post is more pertinent to graduate students (who might not have a solid background in either mathematics or programming). It is not intended for a connoisseur of algorithms.🙂
Cheers!