Again, this post is meant specifically for the undergraduate students (the first timers into the automata theory) – a very brief introduction of FSA: Finite State Automaton (Automata when plural). This post is the second of the four parts: the first part covers an elementary introduction to FSA and DFA (Deterministic Finite Automaton), this part encompasses some common examples illustrating design-strategies for constructing DFA, Part III provides an introduction to NFA (Nondeterministic Finite Automaton) and its equivalence with DFA, and Part IV introduces Pumping Lemma and its usage in the context of FSA.
The post takes up some examples of various types of problems that can be solved by a DFA and discusses, for each problem, the approach to design the corresponding DFA. For the cases when the states are comparatively fewer (manageable), we will use the diagrammatic representation (Transition diagram) of the DFA; for others, we will use the mathematical (or formal) description.
Type I: Pattern Recognition
1. Strings, Substrings & Occurrences
One set of related problems consists of specification as follows:
Problem A: Given an alphabet and a string X (consisting of symbols from the alphabet), DFA should accept
- X exactly.
- All strings Y that have X as a substring i.e. input Y contains X somewhere.
Example
For example, consider an alphabet Σ = {0,1} and X = 00110.
Problem A1: Input should exactly be 00110.
DFA for the example string has been given below. The construction mechanism is similar to the one explained in the previous post.

Proble A2: Input Y = “0010011011″ is valid as it contains X (shown as bold) while input Z = “000111” is invalid.
In this problem, the input does not have to start with “00110” or end after “00110”. Like the previous problem, the states have to remember the symbols of X-like sequence read but unlike it, we can not tell that the input is invalid if the first or second symbols are not 0 or the third and forth are not 1 or the fifth is not 0. “00110” can occur anywhere. Therefore, we do not need the trap-state here. We have to keep looking until we find “00110” and once we have found it, what is remaining of the input will not matter. If we have not found it until the very end of the input, the input is invalid. First symbol of X is 0 which implies that getting a 0 could mean that X might start and that getting a 1 can not start an occurrence of X; therefore, remain in initial state if we get a 1. Thus we get the following:

The question is where the edge for 1 from S1 or for 0 from S2 and so on should go? Consider one such case – Edge for 0 from S2: It signifies that we have already read 00 but then we were expecting 1 but got 0 ⇒ input read until this instant is …000. 000 can not start X, but last two zeroes could mean that we may find X as X starts from two zeroes. Therefore we should now expect 1 next (two zeroes are followed by 1 in X); this is same as being in the state after reading two zeroes i.e. S2. This edge from S2 should go to S2.
Bingo! that is the trick – Go to the state corresponding to longest prefix of X that happens to be the suffix of sequence on the path from the initial state to the current edge.
| edge | sequence on path | X | Longest common suffix of sequence and prefix of X | Next state |
|---|---|---|---|---|
| 1 from S1 | 01 | 00110 | 0 | initial |
| 0 from S2 | 000 | 00110 | 2 | S2 (≡ 00) |
| 0 from S3 | 0010 | 00110 | 1 | S1 (≡ 0) |
| 1 from S4 | 00111 | 00110 | 0 |
Finally, we get the DFA as :

Variants:
- We can use the above DFA, with slight modification, to find all the occurrences of X
– reaching S5 doesn’t make the remaining input insignificant as we might find another occurrence of X. Thus, edges from S5 will follow the longest suffix-prefix trick (0 to S2 and 1 to initial). We will report every time the final state S5 will be reached while reading the input. - We can use the above DFA (the one to find all the occurrences) to accept all the strings that end with X (For example, accepting 11100110, 101000110 etc. while rejecting 1100001, 0000000 etc.)
2. Substring from the Decimal expansion of a rational number
Problem B: Design a DFA that accepts all strings X such that X is a substring of the decimal expansion of a given rational number.
Example
For example, consider the decimal expansion of 1/7.
As 1/7 = 0.14285714285714… = 0.142857
The decimal expansion of a number is its representation in base-10 (i.e., in the decimal system). For example,
223.15 = 2×102 + 2×101 + 3× 20 + 1×2–1 + 5×2–2
The decimal expansion of every rational number (of the form p/q) either terminates or eventually start repeating. More mathematical details can be found here.
The strings like “0.14”, “0.1428571”, “428”, “8571428571” etc. appear as the substring in the decimal expansion of 1/7. All these strings are valid and should be accepted by the DFA.
Note that this is mirror image of Problem A. In Problem A, we designed the DFA for the shorter sequence (pattern) and the input was the longer sequence (text); whereas, here the DFA is for the longer sequence and the input should be a substring in that.
Alphabet of the DFA
Σ is the decimal alphabet (i.e. from 0 to 9) including decimal point.
What should we remember? (i.e. the states of the DFA)
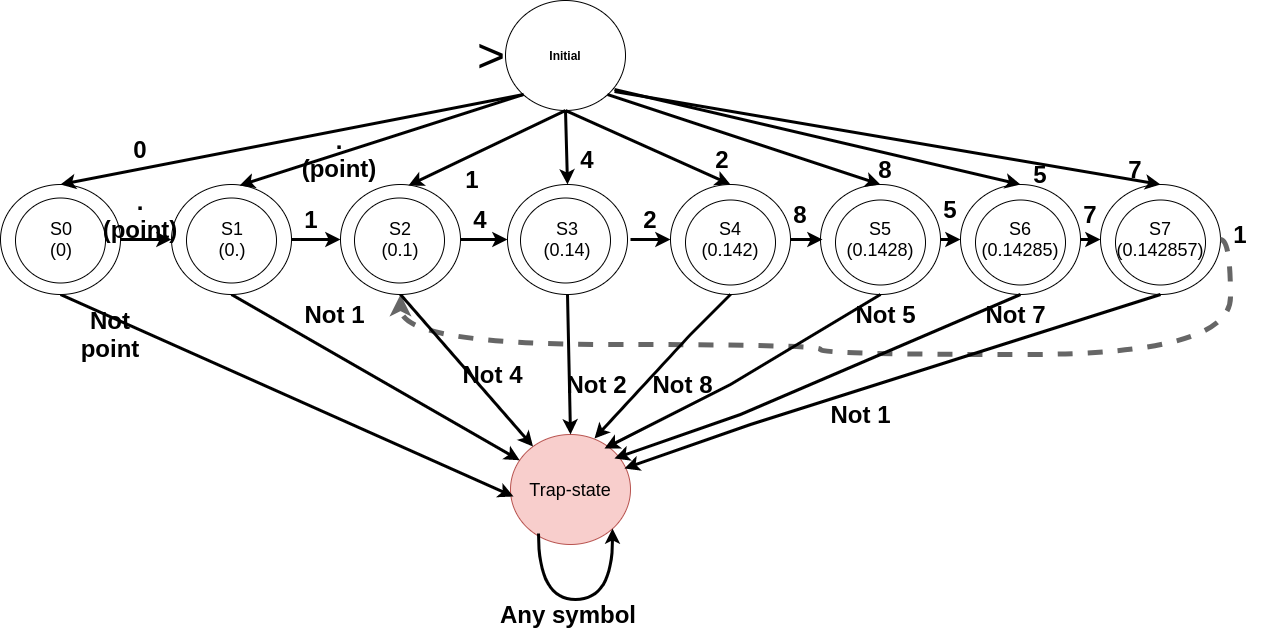
The input read so far. Therefore, the states should correspond to “0” (S0), “0.” (S1), “0.1” (S2), “0.14” (S3), “0.142” (S4), “0.1428” (S5), “0.14285” (S6), and “0.142857” (S7). After that the sequence may start repeating (with the digit after the decimal point i.e. starting from 1 and so on) that can be handled by the edges (transition from S7 to S2 on reading 1). All these states represent the final states. The problem is that any of the states can be an initial state (Occurrence of X can start from any of the position in the expansion). Therefore, we need to be careful while defining the initial state and the transitions from it.
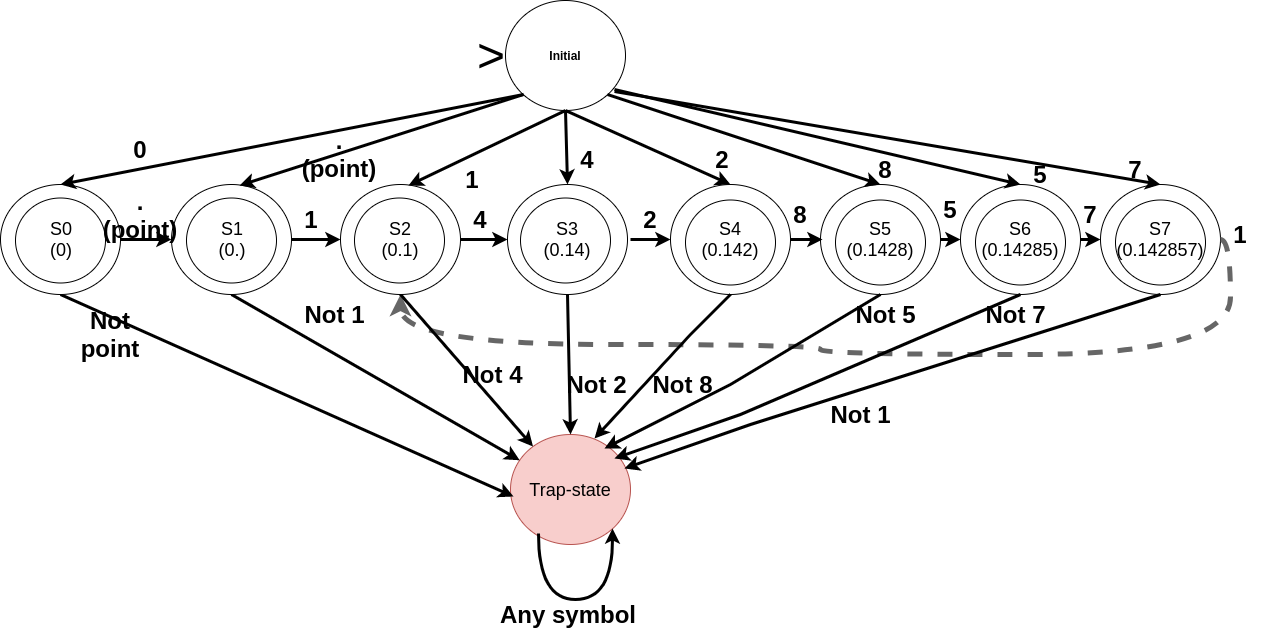
Note that the edges leading to the trap state have been labelled as complements of the symbols (meaning any other symbol from the alphabet than the one specified). To simplify the diagrams, we could completely do away with the trap state. Usually, if transition has not been explicitly defined for an input symbol, we can safely assume that there is an implicit edge corresponding to that symbol switching the current state to the trap state.
We could simplify the DFA by combining the states S7 and S1 (Resultantly, the edge labelled 7 from S6 will go to S1; edge from initial state to S1 will also be labelled with 7).
3. Power of 10
Problem: Design a DFA that accepts all strings X over a decimal alphabet (i.e. from 0 to 9) such that X is 10n for some n ≥ 1.
Example
Any of the strings in the set {“10”, “100”, “1000”, …} is valid. In other words, a valid string should start from 1 and followed by one or more 0. Any other symbol from the alphabet will make the input invalid. Also, any input not starting from 1 or not ending in a sequence of only zeroes (e.g. “000”, “101”, “111”, “1010”) etc. is invalid.
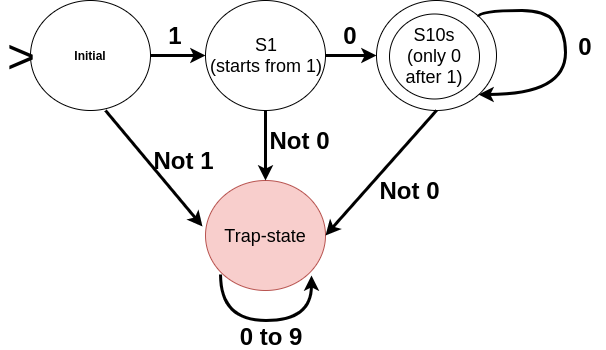
Which states do we need?
- One representing that the input begins with 1 [State S1].
- Another representing that the initial 1 is followed by one or more 0s [State S10s]. It will also be the final state (representing a valid input).
- A trap state representing an invalid input.
DFA for the example string has been given below.
Variants:
- If n ≥ 0 then the input string “1” is also valid; S1 should also be the final state.
- If n ≥ k where k is positive integer > 1, then we need (k-1) additional states between S1 and the final one with an edge from one to the next labelled 0.
Type II: Testing Computations
1. Sum of Two Binary Numbers
Problem: Given three sequences N1, N2, and S over {0,1}, design a DFA that tests whether S represents a valid (correct) binary addition of N1 and N2.
Example
Consider the two inputs given below. The input on the left is valid because S represents the correct binary sum of N1 and N2 whereas the one on the right is invalid.
| N1: 00111 N2: 01010 S: 10001 |
N1: 00111 N2: 01010 S: 11101 |
Design strategy
If we were to test the sum manually, we will do it column-wise moving from right to left, taking care of any carry generated in the previous operation.
Alphabet of the DFA
One symbol read by the DFA can be represented as a column or triplet of the corresponding bits of each: the first number N1, the second number N2, and the sum S. Resultantly, [b1, b2, s] represents one symbol of the alphabet where each of the b1, b2, and s can be either 0 or 1. Note that only 8 such triplets are possible. Therefore,
Σ = {[0 0 0], [0 0 1], [0 1 0], [0 1 1], [1 0 0], [1 0 1], [1 1 0], [1 1 1]}.
What should we remember? (i.e. the states of the DFA)
We need the information whether the previous column led to a carry, in order to test the summation of current column. Thus, we need two states to represent if carry was generated (C) or not (NC). When we start, there is no previous carry. Therefore, the initial state is NC.
To define the transition from each of the two states corresponding to each of the possible input symbol [b1, b2, s], we will add b1 and b2 and the carry information (1 if in C state and 0 if in NC state) and verify if it equals s or not. If the sum is not s, then this column (and hence the overall input) is invalid switching the DFA to the trap state. If it indeed is correct, then the switch will be in accordance with the carry generated by the current column (i.e. if a carry is generated then go to C, otherwise to NC). For instance, consider the transition from C labelled with [0 0 1]. We are in state C (implying that the carry from the previous column is 1). 1 (previous carry) + 0 (b1) + 0 (b2) = 1 which indeed is same as s. Thus it is a valid addition and as this addition doesn’t generate a carry, we must switch to NC state.
If overflow is not allowed, we should end up with no carry being generated by the last column. Therefore, NC is the final state. On the other hand, in case the overflow is ignored, both states are the final states.
The DFA (not allowing an overflow) has been shown below.

2.Modulus/Multiples
Problem: Design a DFA that accepts all strings X representing a number in a numeral system with base b (e.g. a number in decimal or binary system) such that XR (i.e. reverse of the string) is r % (modulus) n, where r and n are decimal numbers.
Example
Consider the decimal number system (base b =10). And, XR ≡ 5 % 7
The string X = “917” should be accepted by the DFA because the reverse of the number ie 719 when divided by 7 gives 5 as the remainder (%). On the other hand “112” is invalid ( since 211 % 7 = 1).
Design strategy
Note 1:
The expansion of a number say w of say k digits (w = dk…d3d2d1) in base-b number system is as follows:
dk…d3d2d1 = dk×bk-1 + … + d3×b2 + d2×b1 + d1×b0
Remember that,
1. (x + y) % n = ((x % n) + (y % n)) % n
2. x × y % n = ((x % n) × (y % n)) % n
Thus, we can compute w % n as follows:
For each term i, such that 0 < i ≤ k,
ri = ((di × (bi-1 % n) % n) + ri-1) % n, where ri is the remainder of the number up to digit i.
As r0 = 0, computing from right to left in the above fashion, rk will be the final remainder.
Note 2:
bi % n = ((b % n)(bi-1 % n)) % n
Reading XR from right to left is same as reading X left to right.
Alphabet of the DFA
Σ is the alphabet of the number system.
States and the transition function
To use our strategy, for every ith digit read from the input, we should know the remainder ri-1 (from the calculations up to that digit) and the result of (bi-1 % n). As (bi % n) will start repeating (periodic/cyclic) after a finite number of steps, we can pre-calculate these terms and remember them. Let us call it p.
Thus a state is a pair (ri, pi) where pi corresponds to (bi % n) for some i and ri corresponds to one of the possible remainders i.e. from 0 to n-1.
A transition on reading a symbol α from state (ri, pi) will take us to the state ( (((αpi % n) + ri) % n), pi+1).
Initial state will be (0, 1) because initial remainder is zero and p0 = (b0 % n) = 1.
The final states will be all the states with ri = r (irrespective of what the corresponding pi is ). It can be represented as (r, *).
For the given example, b=10, n=7, r=5. Let us calculate p first.
| pi | (b × pi) % n | pi+1 |
|---|---|---|
| 1 | (10 × 1) % 7 | 3 |
| 3 | (10 × 3) % 7 | 2 |
| 2 | (10 × 2) % 7 | 6 |
| 6 | (10 × 6) % 7 | 4 |
| 4 | (10 × 4) % 7 | 5 |
| 5 | (10 × 5) % 7 | 1 |
Thus the DFA can be specified as follows:
ℳ = (Q, Σ, s, F, δ) where
Q is set of the states (ri, pi) where ri takes values from 0 to 6 and pi is an element of {1,3,2,6,4,5} (see the table),
Σ is {0,1,….,9},
s is (0,1),
F is all states (5, *) [i.e. (5, 1), (5, 3), (5, 2), (5, 6), (5, 4),and (5, 5)]
δ is given as the following transition table:
(ri, pi) ——[on reading α from Σ] ——> ( (((αpi % 7) + ri) % n), pi+1)
where corresponding pi+1 is given in the table above.
Variants:
- The string X itself (not its reverse) has to be congruent to r % n (X ≡ r % n).
The strategy to design this DFA makes use of the following way to represent the expanded form of X:
dk…d3d2d1 = dk×bk-1 + … + d3×b2 + d2×b1 + d1×b0 =d1 + b(d2 + b(d3 + b(…..b(dk))))
On reading ith digit di, the number becomes wi = (b × wi-1) +di. Therefore,
wi % n =((b × wi-1 % n) +di) % n.
Thus, a state in this case needs to remember the remainder after reading each digit which is from 0 to n-1. Let Si be a state corresponding to remainder equal to i. Si is the initial state. Sr is the final state.
The transition function:Si ——[on reading α from Σ] ——>Sj where j = (b × i % n) + α) % n. - X is a multiple of n is same as (X ≡ 0 % n)
For example, following is the DFA that accepts all strings X over {0, 1} (binary system) such that X is the binary representation of a number that is a multiple of 5.
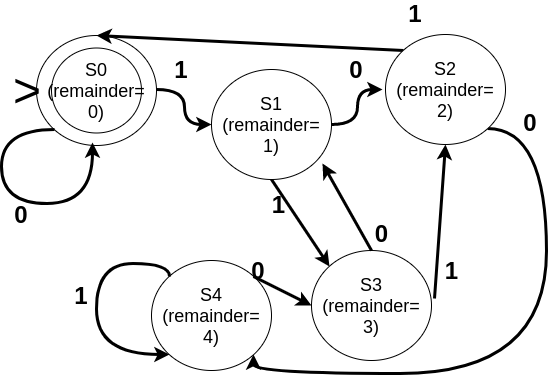 Consider the transition from S3 labelled 1: α=1, i =3, j = (( 2 × 3) % 5) + 1) % 5) = 2. Thus it switches to S2. We could have pre-calculated the table for (b × i % n) for faster computations.
Consider the transition from S3 labelled 1: α=1, i =3, j = (( 2 × 3) % 5) + 1) % 5) = 2. Thus it switches to S2. We could have pre-calculated the table for (b × i % n) for faster computations. - n=2 is a special case. (X ≡ 0 % 2) means that it is even and (X ≡ 1 % 2) implies that X is odd.
Type III: Counting related
1. kth position from the end
Problem: Design a DFA that accepts all strings X over an alphabet {0, 1} such that kth position of X is 1 where k is a given constant ≥ 1.
Example
Let k = 4 i.e. the fourth character from the end of X should be 1. If the length of X is smaller than 4 or the fourth character from the right is 0, it should be invalid. Therefore, input like “11111″, “1001010″, “001000″ etc. are valid whereas “10”, “111”, “10111”, “010000” etc. are invalid.
Design strategy
We will remember the last k characters read. Initially, we will keep remembering all the symbols until k symbols have been collected. When we have already read the k symbols, every new symbol will require us to remember that forgetting the first one.
Thus, a state represents a sequence of last k symbols read (dk…d3d2d1). To simplify the specification of the transition function, we can use an extra symbol (let it be ε) to represent an empty position in the sequence of k symbols. The initial state will be a sequence of k empty positions. The final state will have dk = 1 (other di do not matter).
The corresponding DFA for the considered example has been specified below:
ℳ = (Q, Σ, s, F, δ) where
Q is set of the states (d4 d3 d2 d1) such that di takes values from {0, 1, ε} where ε is an symbol representing an empty position in the remembered sequence.
Σ is {0, 1},
s is (ε ε ε ε),
F is all states (1 d3 d2 d1)such that di (1 ≤i ≤3) takes values from {0, 1},
δ is given as the following transition table:
(d4 d3 d2 d1) ——[on reading α from Σ] ——> (d3 d2 d1α)
2. Number of given substrings
Problem: Design a DFA that accepts all strings X over an alphabet {0, 1} such that it has at least n number of occurrences of substring Y where n is a given constant ≥ 1.
Example
Let Y =” 001″ and n = 3 i.e. all the strings that have at least 3 number of occurrences of “001” are valid. Therefore, input like “0011001000111″, “1001000010100111001001″ etc. are valid whereas “10”, “111”, “10111”, “010000”, “00110010″ etc. are invalid.
Design strategy
Similar to the problem of kth position, we will remember the last k characters read where k is the length of Y. In addition, we need a counter to keep track of the number of occurrences of Y. Every time the current symbol leads to the remembered sequence being equal to Y, we increase the counter by 1 until we reach n. Once we reach n, the input is valid and the rest of the input sequence is irrelevant. We can stop remembering the symbols and updating the counter; staying in that state for the rest of the input.
Thus, a state represents a sequence of last k symbols read (dk…d3d2d1) and counter C. If any di = ε, C will be zero (we increment the counter only after seeing Y). And C = n, only for dk…d3d2d1= Y (we stop the increment after that).
The corresponding DFA for the considered example has been specified below:
ℳ = (Q, Σ, s, F, δ) where
Q is set of the states (d3 d2 d1; C) such that di takes values from {0, 1, ε} where ε is an symbol representing an empty position in the remembered sequence; and C is a counter (C = 0 if any di = ε; and ford3d2d1= 001, C = 3; otherwise it is in the range 0 to 2),
Σ is {0, 1},
s is (ε ε ε; 0),
F is all states (0 0 1; 3),
δ is given as the following transition table:
(d3 d2 d1; C) ——[on reading α from Σ] ——> 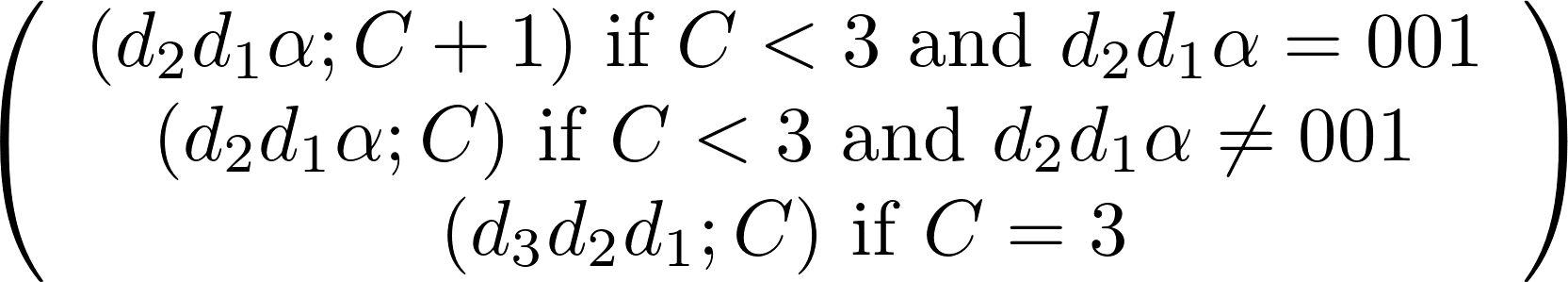
Variants:
- If Y must have an occurrence ≤ n, then C = n+1 will make it invalid and act as the trap state. While all the states (d3 d2 d1; C) such that di is {0, 1} and C ≤ n will be the final states.
- If two or more substrings have been given whose number of occurrences must specify some criteria, we will need that many counters (one corresponding to each Y) and k symbols will be remembered where k is the length of the longest Y. The increment rules will be guided by the relationship of these substrings.
Type IV: Miscellaneous
1. Unary numbers
A Unary system is base-1 numeral system. The alphabet is a single symbol (arbitrarily chosen 1). To represent a natural number n in this system, 1 will be repeated n times.
For example, 5 is represented by 11111 and 2 is represented by 11 in this system.
Problem: Design a DFA that accepts all the unary strings X (i.e. over an alphabet {1}) such that X represents a multiple of a constant natural number n.
Example
Let n = 5 i.e. all strings with number of 1s = 5, 10, 15 etc. should be accepted. In other words, a string X is valid if the length of X ≡ 0 % 5.
Design strategy
We need to remember (L % n) where L is the length of the string seen (correspondingly the number of 1s => the number L). Therefore, states corresponding to every i from 0 to n-1 are required. Each symbol read (i.e. 1) takes us from a state Si to the stateS(i+1)%n. S0 is the initial as well as the final state.
The DFA can be shown as:
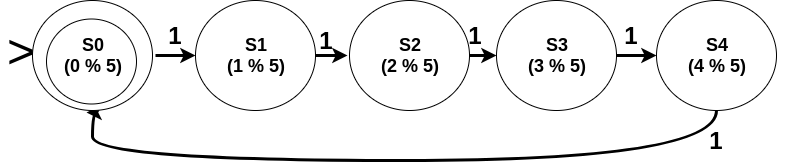
2. Odd/Even Length
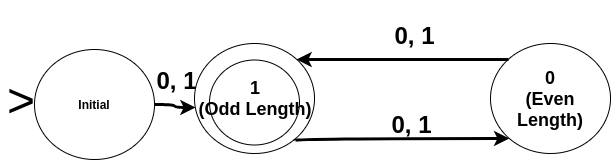
Problem: Design a DFA that accepts all strings X over an alphabet {0, 1} such that its length is odd (or even).
Example
For odd length strings to be valid, inputs like “001” (length = 3), “111”(length = 3), “10101” (length = 5) etc. should be accepted by the DFA whereas “10” (length = 2), “0111” (length = 4) etc. should be rejected.
Design strategy
We need to remember the (L % 2) where L is the length of the string already seen. It will be zero (=> even) or 1 (=> odd). Every symbol read will increase the length by 1, thus switching from even to odd and from odd to even. The corresponding DFA is
Variants:
- For even length (considering 0 to be even), the initial state and the even length state can be combined in one.
- DFA that accepts all string X over {0. 1} such that X has odd number of 0s and even number of 1s (or any such combination).
A state will remember the number of 0s % 2 and the number of 1s % 2 i.e. states correspond to (0=odd, 1=odd), (0=odd, 1=even), (0=even, 1=odd), (0=even, 1=even).
Reading a symbol will switch the corresponding counter between even and odd while keeping the other same. - If two or more substrings have been given whose number of occurrences must specify some criteria, we will need that many counters (one corresponding to each Y) and k symbols will be remembered where k is the length of the longest Y. The increment rules will be guided by the relationship of these substrings.
This completes the discussion, broadly covering the different types of DFA designing problems. Of course, these can be mixed and matched to solve a general problem. The next part will talk about the non-deterministic finite automaton.
Epilogue:
Please pardon the verbosity, oversimplification, and baby-steps. This part of the post is also more relevant to undergraduate students. Move onto the next parts .🙂
Cheers!
Ritu, this has been incredibly helpful, thank you so much for the precious help!! Any chance you will be posting the two remaining parts soon?
Thank you Teresa! Hope you find the next two parts beneficial as well.