Again, this post is meant specifically for undergraduate students (first timers into the automata theory) – a very brief introduction of FSA: Finite State Automaton (Automata when plural). This post is the third of four parts: the first part covers an elementary introduction to FSA and DFA (Deterministic Finite Automaton), the second part encompasses some common examples illustrating design-strategies for constructing DFA, this part provides an introduction to NFA (Nondeterministic Finite Automaton) and its equivalence with DFA, and Part IV introduces the Pumping Lemma and its usage in the context of FSA.
The post inrtoduces an NFA, discusses its equivalence with DFA in terms of the expressive power, and exemplifies the situations when building an NFA makes our lives easier rather than constructing the corresponding DFA. Of course, the equivalent DFA can be drawn if one requires so.
NFA:
As has been described in Part I, a non-deterministic finite automaton allows for transition to more than one state on reading an input symbol; in addition, empty-transitions (ε-transitions) are also possible which correspond to changing state without reading a symbol.
It is usual to distinguish NFA (with no empty transitions) from NFA-∈ (with empty transitions). Here, we will make no such distinction as NFA with empty-transitions is simply a more general variant.
Mathematical description –
Mathematically an NFA can be represented as a 5-tuple ℳ = (Q, Σ, s, F, δ) where
Q is a finite set of states,
Σ is an alphabet (set of symbols of the input),
s ∈ Q is the initial state,
F ⊆ Q is the set of the final states,
δ , the transition function, is a function from Q × Σ to 2Q (i.e. the power-set of the states, in contrast to a single state in case of DFA)
Diagrammatic description –
There may be many edges labelled with the same input symbol going from a state to multiple different states. Thus, the current state the NFA is in, is defined by a set of states (rather than a single state). And, there will be edges labelled with ε; we will call the transition using this edge as an empty-move. Moreover, it is not necessary to define all the transitions, from a state, corresponding to each input symbol of the alphabet. An input will be valid (or accepted) if at least one transition-sequence that is followed on reading the input leads to some final state.
A simple example –
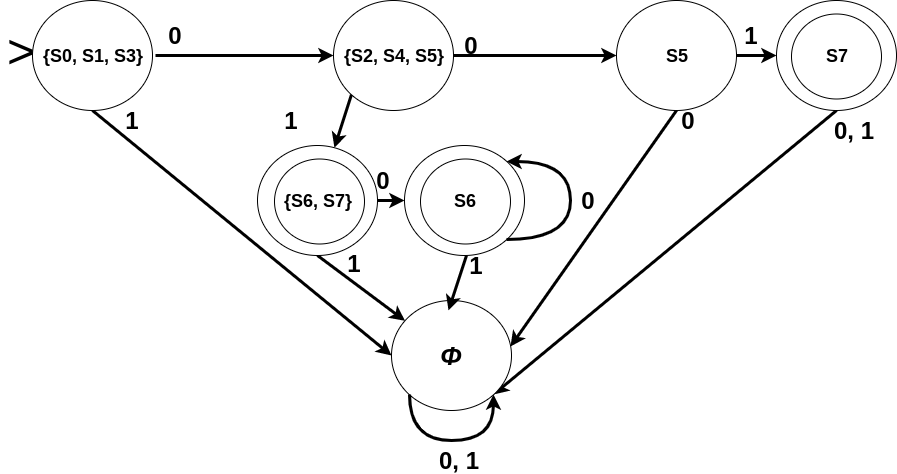
As mentioned earlier, an NFA, instead of being in a single state, may be in a set of states (a subset of Q) at one instance. Let us represent this set of states as active states or an active set. On reading a symbol of the input, the new set of active states is derived by taking union of all the sets of states that can be reached from each of the states which is active currently. Consider an NFA given below (Empty transitions are shown with label E. Please ignore the typo: hanging 1 under S7.):
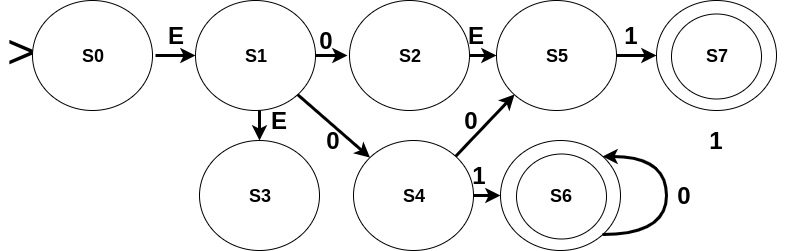
Let’s see how an input (say “01”) will be read in this NFA. State S0 is the initial state but an empty-transition takes us from S0 to S1. Further, an empty-transition from S1 takes us to S3. Therefore, S0, S1, and S3 all serve as initial states. Reading “0” we move from S0 to nowhere; from S1 to S2 and S4; and from S3 to nowhere. Moreover, S2 can make an empty-move to S5. Overall, on reading “0” the set of current (or active) states becomes {S2, S4, S5}. Now the next input symbol is “1”. S2 leads us nowhere; S4 to S6; and S5 to S7. Also, none of these states (i.e. S6 and S7 ) have empty-moves. Hence, after reading “1” we get the active set of states as {S7, S6}. The input ends here. As S6 is a final state in the current/active states when the input ended, the input “01” is accepted by this NFA.
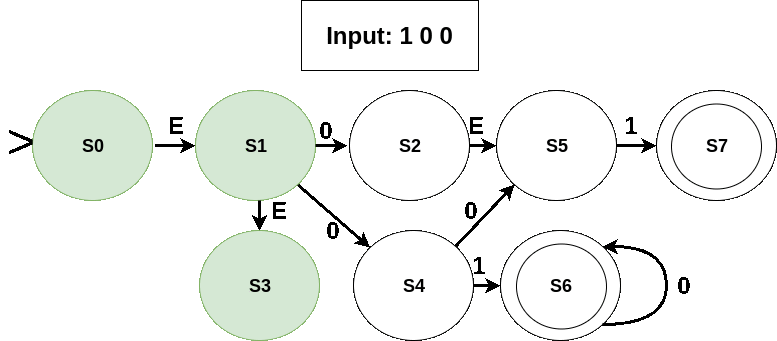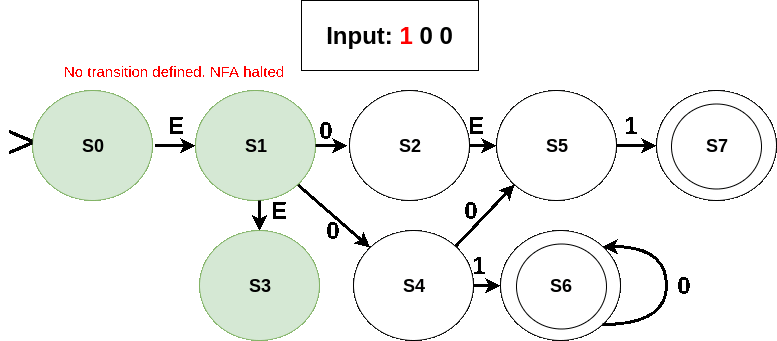
Note that if there had been no final states in the active state at the end of input, we would have said that the input is rejected. The input would also said to be rejected if the NFA gets ‘halted‘ (i.e. there is no way out of any of the current active states on reading the next symbol of the input) before the input ends.
Working of the NFA for some input sequences is shown in the following figures (current symbol being considered is shown in red; active states in green; edges taken and the next state in red):
- A valid sequence
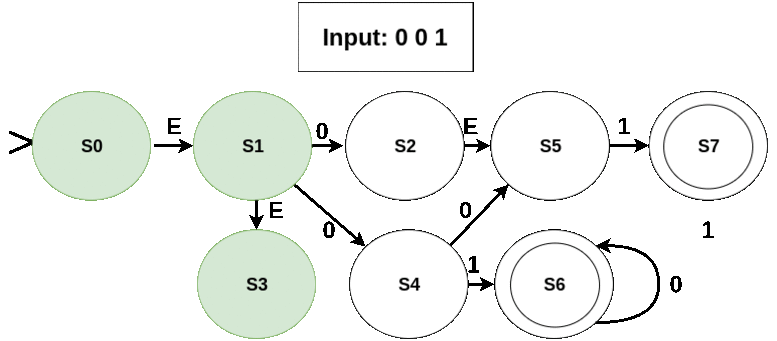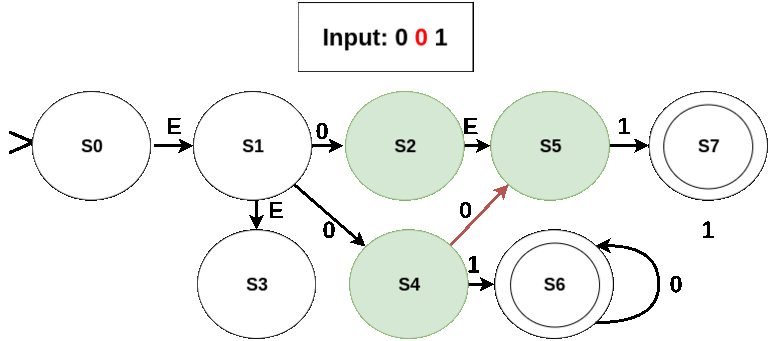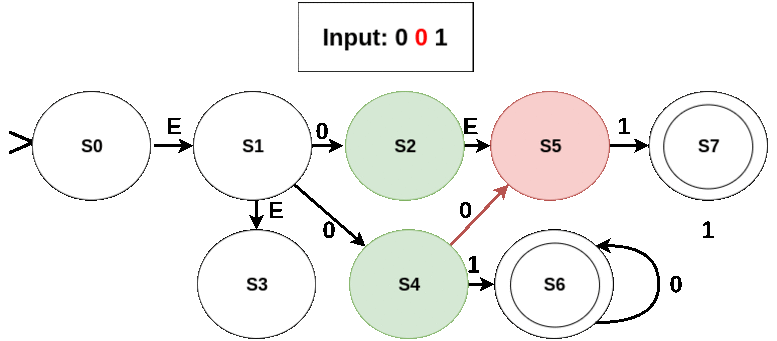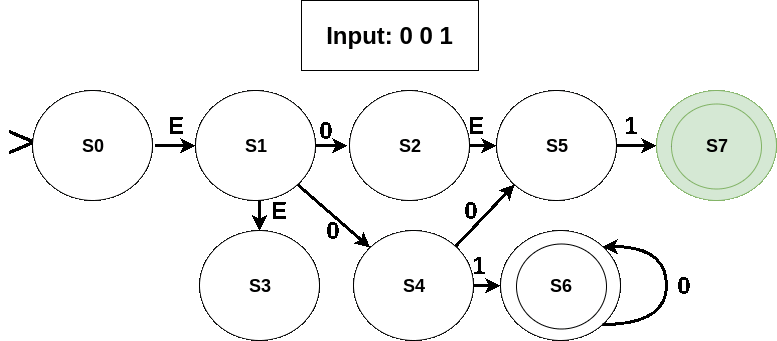
- An invalid seqeunce: No state is accepting in the last active set (which is just {S5}).
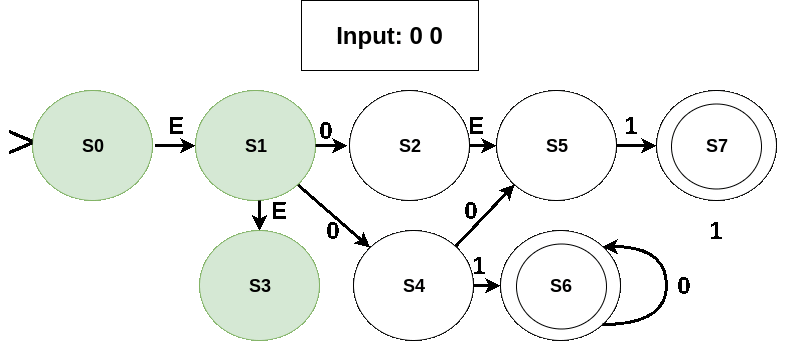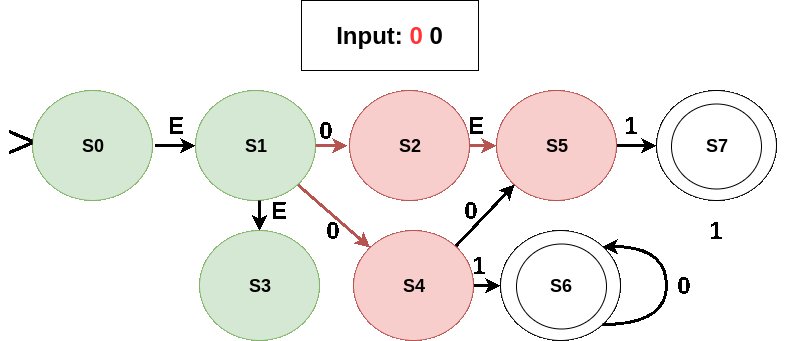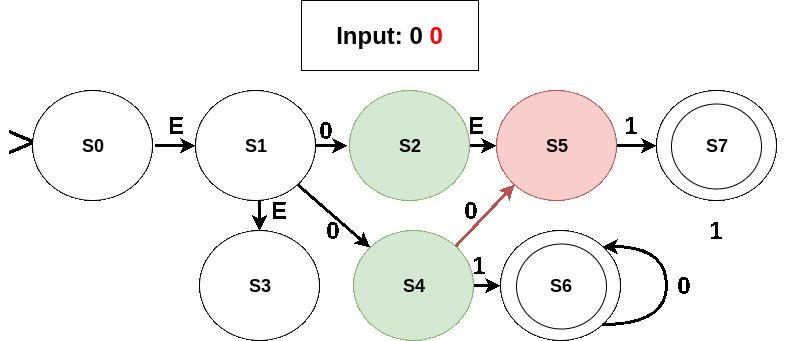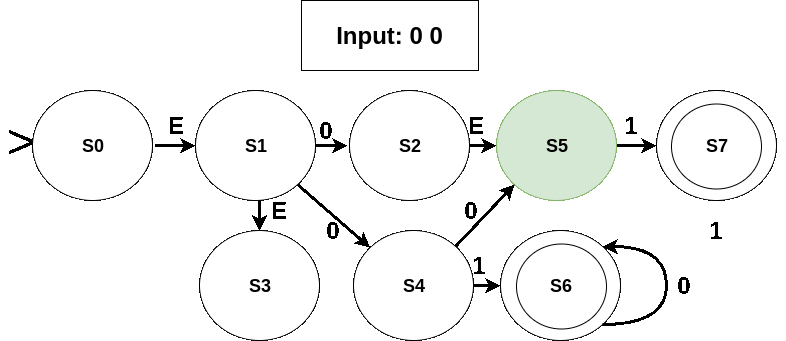
- An invalid sequence: no transition out on reading symbol 1 and input has not ended.
NFA to DFA
Although an NFA has this ability to make multiple or empty transitions, yet it is not any more powerful than a DFA in terms of its expressiveness. Note that the set of all the input sequences which are accepted by a finite automaton (DFA or NFA), is said to be its language; or the automaton is said to express that language. The statement that the expressive power of an NFA is same as that of DFA essentially means that for every language that is accepted by an NFA, an equivalent DFA can be constructed to accept the same language. On the other hand, if a language can not be expressed by a DFA, no NFA would be able to express that.
Algorithm –
The process of building the equivalent DFA is quite mechanical. Here is the intuition behind it: the state an NFA is in, is a set (subset of Q); that set can be made to represent a single state of the equivalent DFA. So, if we build the power-set (a set of all possible subsets of a given set) of Q (i.e. 2Q) such that each set in this power-set represents a state of the equivalent DFA then the transitions corresponding to each symbol of the alphabet in NFA will take us from one such new state (effectively representing current active set) to another (representing the next active set). The transitions that have not been defined can all go to the state corresponding to the empty set. And that’s it! This technique is called the “subset construction algorithm“. Only, we will use a ‘lazy’ approach to build the subsets, meaning that a subset will be constructed only when it is needed.
This technique can be implemented in a couple of different ways. One such possibility is the following implementation of the algorithm:
- Preprocessing: Build a table (let’s call it NFA-transitions) – each row corresponds to a state in Q and each column corresponds to every symbol in the alphabet. An additional column corresponds to ∈. In the cell corresponding to a row (state) say S, and a column (symbol), say α, we write the set of all the states that can be reached from S on reading symbol α (leaving out empty moves). In the cell corresponding to row S and ∈, we write the set of all states, including S itself, that can be reached from S following only empty transitions.
Note that the set of states reached from a given state by just following the empty transitions, including the state itself, is called the ∈ – Closure of that state.
- Start building another table (let’s call it DFA-transitions): A column corresponding to each symbol in the alphabet. A row will correspond to a subset of Q as and when a new subset is created.
-
- Initial Step: Start from the initial state s: consider its set of states corresponding to ∈ – Closure of s (as given in row s and column∈ of NFA-transitions). Add it as the first row in DFA-transitions.
- Repeat: To find the subset in the cell (in DFA-transitions) of a row corresponding to a subset (say P) and column corresponding to symbol α, we take the union of all the sets in the cells [pi,α] of NFA-transitions, where pi is a state in P, to get a intermediate subset; then take union of the ∈ – Closure of each state in this partial subset. In effect, we are finding the next active set on reading α from the current active set (i.e. P). If the resulting subset is a new one (i.e. not already added as a row in DFA-transitions), add it as the new row. Recall that if there is no state in the resulting subset (equivalent to the empty set), it amounts to halting of NFA and thus it represents a trap-state. Also note that if any pi is final in the NFA, P should be marked final.
- Stop: When the table is complete and there is no new row to add in the table.
The resulting table is the transition function of the equivalent DFA, the subset of each row is its one state, the subset of the first row is its initial state, all the subsets having at least one final state of the NFA are its set of final states. Of course, the alphabet remains the same.
Example –
Let’s convert the NFA from the above section into its equivalent DFA. The table NFA-transitions is as follows:
| State | 0 | 1 | ∈ |
|---|---|---|---|
| S0 (initial) | Φ | Φ | {S0, S1, S3} |
| S1 | {S2, S4} | Φ | {S1, S3} |
| S2 | Φ | Φ | {S2, S5} |
| S3 | Φ | Φ | {S3} |
| S4 | {S5} | {S6} | {S4} |
| S5 | Φ | {S7} | {S5} |
| S6 (final) | {S6} | Φ | {S6} |
| S7 (final) | Φ | Φ | {S7} |
Construction of the table DFA-transitionsis: We start from[S0,∈] ≡ {S0, S1, S3} as the first row. For the cell under 0 — Take union of the cell [S0, 0] (i.e. Φ), the cell [S1, 0] (i.e.{S2, S4}), and the cell [S3, 0] (i.e. Φ) which gives {S2, S4} as the intermediate subset. Then take union of the cell [S2,∈] (i.e.{S2, S5}), and the cell [S4,∈] (i.e. {S4}) which yields {S2, S4, S5}. Add {S2, S4, S5} as the new row as it, currently, is not in the table. Follow the same for symbol 1. And continue filling each cell until there is no cell left to fill. The resulting table is as follows:
| State | 0 | 1 |
|---|---|---|
| {S0, S1, S3} (initial) | Φ ∪ {S2, S4} ∪ Φ ≡ {S2, S4} <= Intermediate set {S2, S5} ∪ {S4} ≡ {S2, S4, S5} <= ∈ – Closure Result: {S2, S4, S5} |
Φ ∪ Φ ∪ Φ ≡ Φ <= Intermediate set Φ <= ∈ – Closure Result: Φ (Φ is a trap state. Thus it does not need adding in the table.) |
| {S2, S4, S5} | Φ ∪ {S5} ∪ Φ ≡ {S5} <= Intermediate set {S5} <= ∈ – Closure Result: {S5} |
Φ ∪ {S6} ∪ {S7} ≡ {S6, S7} <= Intermediate set {S6} ∪ {S7} ≡ {S6, S7} <= ∈ – Closure Result: {S6, S7} (It is a final state. Recall we need at least one to be final in the subset to declare it final and it has two final states.) |
| {S5} | Φ <= Intermediate set Φ <= ∈ – Closure Result: Φ |
{S7} <= Intermediate set {S7} <= ∈ – Closure Result: {S7} (It is a final state as it has one final state.) |
| {S6, S7} (final) | {S6} ∪ Φ ≡ {S6} <= Intermediate set {S6} <= ∈ – Closure Result: {S6} (It is a final state as it has one final state.) |
Φ ∪ Φ ≡ Φ <= Intermediate set Φ <= ∈ – Closure Result: Φ |
| {S7} (final) | Φ <= Intermediate set Φ <= ∈ – Closure Result: Φ |
Φ <= Intermediate set Φ <= ∈ – Closure Result: Φ |
| {S6} (final) | {S6} <= Intermediate set {S6} <= ∈ – Closure Result: {S6} (It is a already in the table.) |
Φ <= Intermediate set Φ <= combined ∈ – Closure Result: Φ |
Note that the table has an implicit row for Φ, it stays in Φ for each symbol of the alphabet (as it corresponds to a trap-state).
The resulting DFA is given below:
Why NFA?
DFA is essentially a specialised NFA (with exactly one transition defined for each and every alphabet-symbol and no empty-transition defined) and an NFA can be converted into an equivalent DFA using the algorithm given above. The question now arises: if DFA and NFA are equivalent in the power to express, why do we need NFA at all?
The answer is based on the following two advantages of NFA over DFA:
- The equivalent DFA can have exponential number of states (as is clear from the fact that states of the equivalent DFA is a subset of the power-set of states of the NFA i.e. 2Q).
- It is easier to describe some languages using NFA than using a DFA. We will see a few examples.
Examples of NFA
Recall that the set of all the input sequences that are accepted by a finite automaton is called its language. It might be a finite or infinite set. Following are some scenarios where expressing a language can be done more conveniently using an NFA.
Union
Problem: If M1 and M2 are two DFAs that accept languages L1 and L2 over an alphabet, respectively, design a finite automaton M that accepts all strings X such that X is in L1 ∪ L2.
Mathematically, L ≡ L1 ∪ L2 ≡ {x | x ∈ L1 OR x ∈ L2 }. Here ∈ implies the set-membership.
Example
If M1 accepts {“11”, “001”, “111”} and M2 accepts {“11”, “0101”}, then M should accept L1 ∪ L2 ≡ {“11”, “001”, “111”,”0101″}.
Design strategy
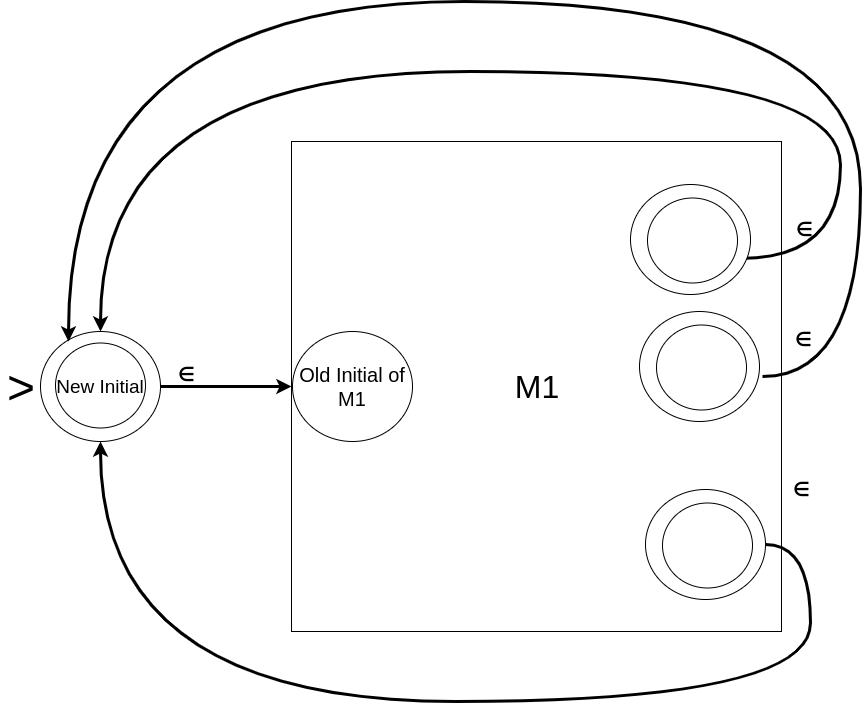
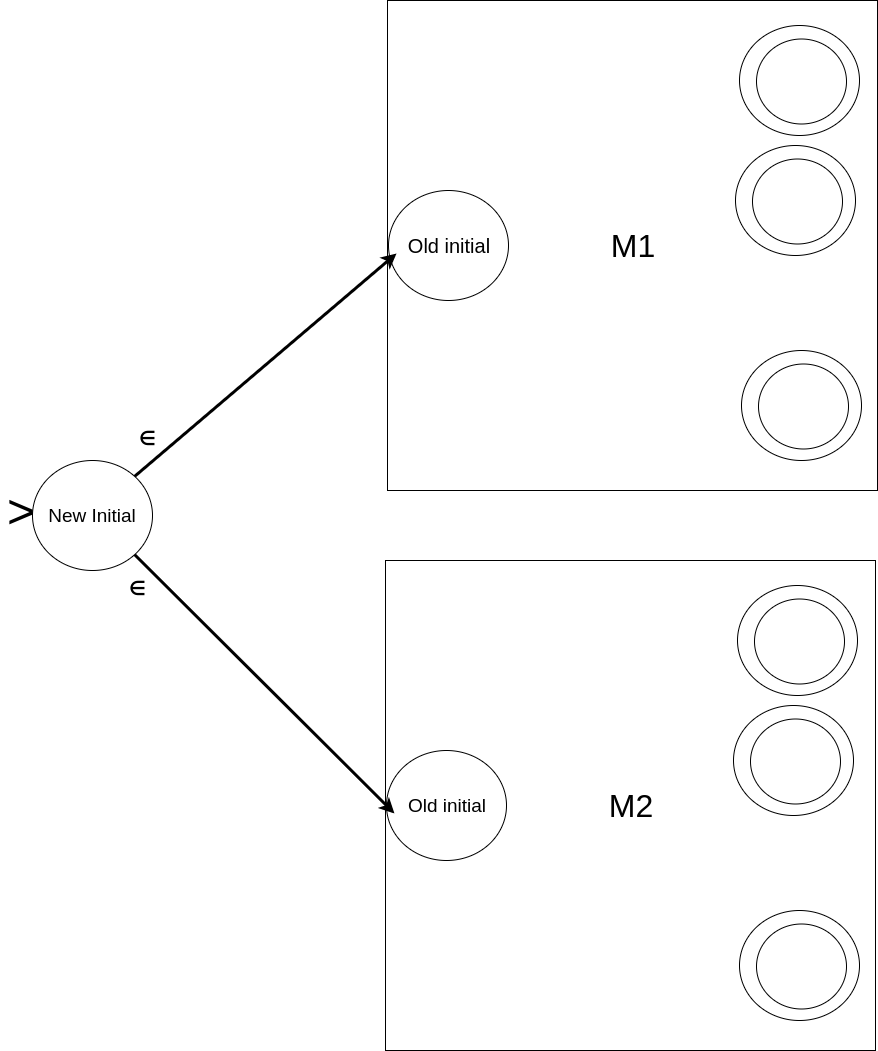
Here, we will combine M1 and M2 to produce the desired result. The set of the states will be the combined (or union) set of the states coming from M1 and M2; and the alphabet will remain the same. The transition function within both M1 and M2 remains the same. Any string in L1 or L2 should be accepted => final states of M1 and M2 remain the same. But we now have two initial states (one from both, M1 and M2). All we need to do is make them ‘non-initial’ and add a new initial state with empty-transitions to each of the old initial states. In effect, we will start from the new initial state, take the empty-transition (without consuming any input symbol), and will reach the old initial states. From there, if the input reaches a final state of either M1 or M2, it reaches in essence the final state of M.
Diagrammatically, it can be shown as follow:
Mathematically, it can be described as follows:
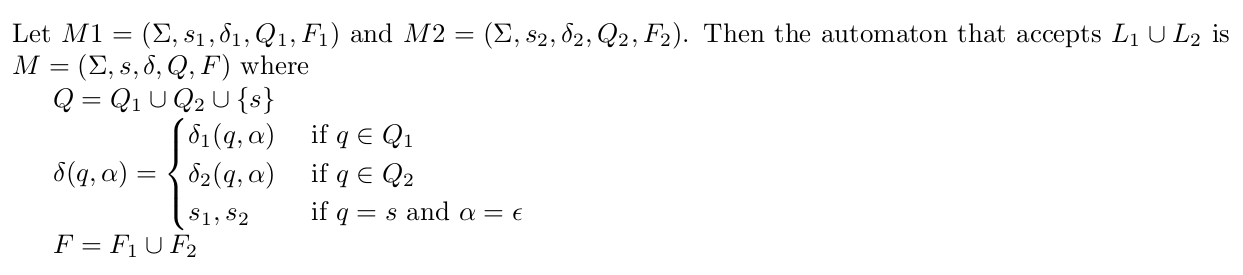
An alternative description can be expressed as:

Concatenation
Problem: If M1 and M2 are two DFAs that accept languages L1 and L2 over an alphabet, respectively, design a finite automaton M that accepts all strings X such that X is in L1.L2.
Mathematically, L ≡ L1 . L2 ≡ {xy | x ∈ L1 AND y ∈ L2 }. Here ∈ implies the set-membership.
Example
Concatenation (represented by “.” i.e. a dot) means that the input sequence (string) is some string from L1 followed by some string from L2. For instance, if M1 accepts {“11”, “001”} and M2 accepts {“11”, “0101”}, then M should accept L1.L2 ≡ {“1111”, “00111”, “110101”,”0010101″}.
Design strategy
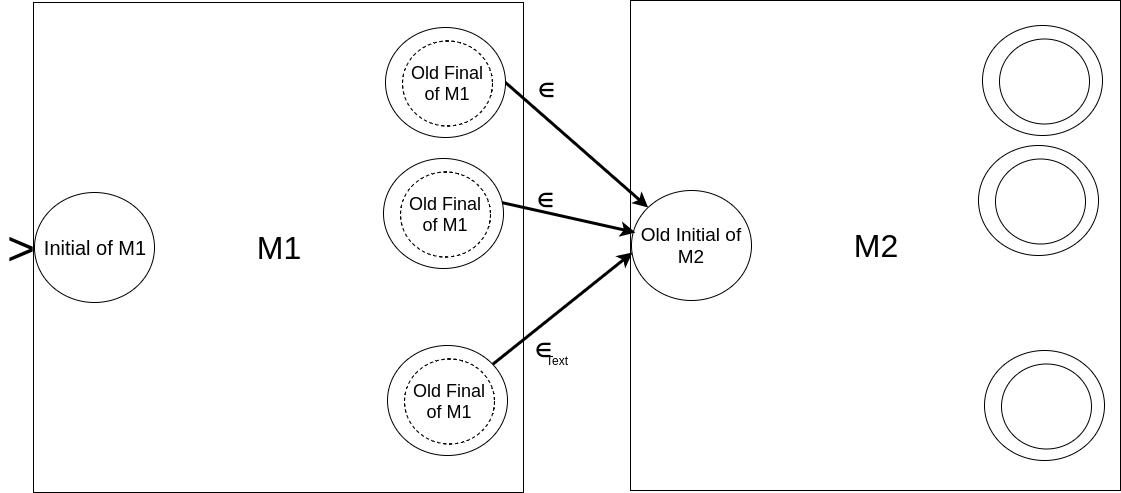
Again, we will combine M1 and M2 to produce the desired result. The set of states will be the combined (or union) set of the states coming from M1 and M2; and the alphabet will remain the same. Transition function within both M1 and M2 remains the same. Any string in L1 must be followed by another from L2 to be accepted => final states of M is same as that of M2 and final states of M1 are not final any longer. The valid sequence should start from a string of L1 => Initial state of M1 is the initial state of M and initial state of M2 is no longer initial. Also, once the part of the input from L1 is over, the remaining part immediately after it should be from L2. Thus, we need empty-transitions (which do not consume any input symbol) from the final states of M1 to the initial state of M2. In effect, we will start from the initial state of M1, if we reach its final state ( => the first part of the input comes from L1) then we take the empty-transition (without consuming any input symbol) and reach the initial state of M2. From there, if the input reaches its final state ( => the second or last part of the input comes from L2), it reaches the final state of M2 which is the same as the final state of M.
Diagrammatically, it can be shown as follow (the dotted inner circle implies that this is not a final state any longer):
The mathematical description is:
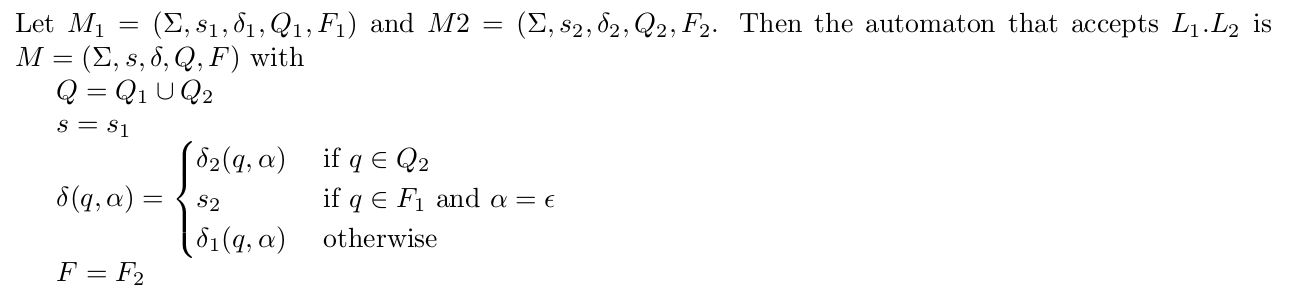
Kleene Star
Problem: If M1 is a DFA that accept language L1 over an alphabet then design a finite automaton M that accepts all strings X such that X is in L1*.
Mathematically, L ≡ L1* ≡ {x1x2x3…xi |xi ∈ L1 and i ≥ 0 }. Here ∈ implies the set-membership.
L10 is empty string; L11 is L1; L12 is concatenation of any two strings from L1; and so on.
L1* ≡L10 ∪ L11 ∪ L12 ∪ …
Thus L1* is an infinite language.
Example
Kleene Star (represented by “*” i.e. an asterisk as superscript) means that the input sequence (string) is some string from L1 followed by the same or another string from L1 and so on. It also includes the empty string. For instance, if M1 accepts {“11”, “001”} then M should accept L1* ≡ {∈, “11”, “001”, “1111”, “00111”, “11001”,”001001″, …}.
Design strategy
Here, we will modify M1 to produce the desired result. The set of the states will be the same as the set of the states coming from M1; and the alphabet will remain the same. The transition function within M1 remains the same. Any string in L1 may be followed by zero or more strings from L1 to be accepted => as soon as the part of the sequence corresponding to one string from L1 ends, another string of L1 must start immediately => final states of M1 should lead back to its initial state using empty-moves. As M should accept an empty string also, the initial state should be final. What if the initial state is not final? We add another initial state which is also final and add an empty-transition from it to the old initial state.
Diagrammatically, it can be shown as follow:
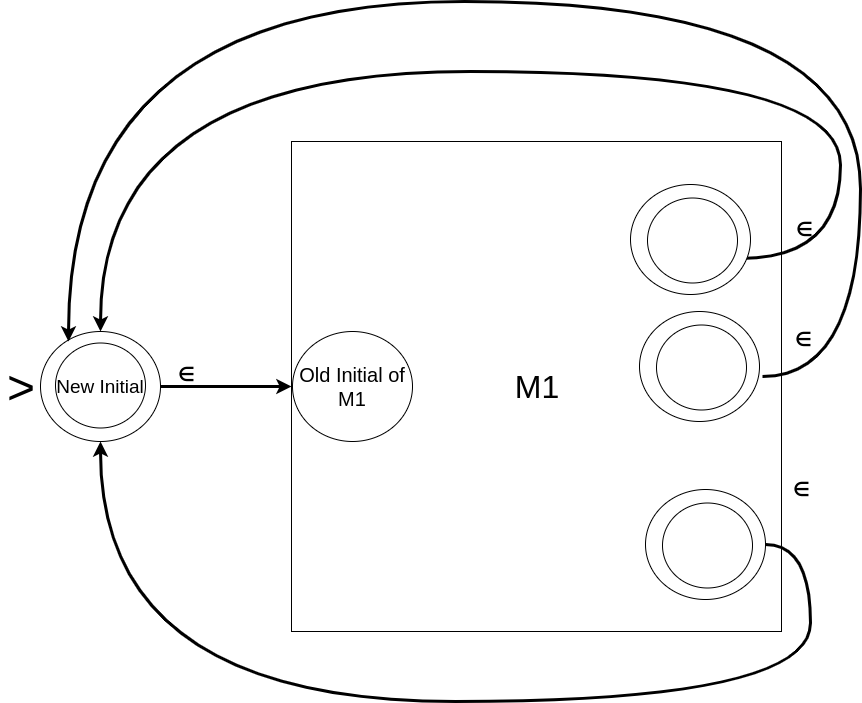
Mathematically,

An important point to note here is that simply making the old initial state to be final (instead of adding a new initial state to make it final) will not work in all cases. Consider, for instance, a case when the initial state is non-final and a symbol, say 0, makes a loop on it (i.e. 0 takes it back to itself); here, a sequence of 0s will be rejected. If we had made it final for M then the sequence of 0s would have been accepted by M, which is definitely wrong. Therefore, it is safer to add a new initial state and make that final.
Similarly the FA accepting the complement of a language L1 can be computed by changing all the final states to non-final and all the non-final states to final. Note that the complement of a language i.e. L ≡ L1C ≡ {x | x ∉ L1 } accepts all strings which are not in L1 (rejected by M1) and reject those which are in L1 (i.e. which M1 accepts).
In the same sense, intersection of languages i.e. L ≡ L1 ∩ L2 ≡ {x | x∈ L1 AND x∈ L2 } accepts a strings if and only if it is in both L1 and L2 (i.e. accepted by both M1 and M2).
We can make use of the property: L1 ∩ L2 ≡ (L1C ∪ L2C)C
Build NFAs for complement of L1 and complement of L2 separately, combine them using rules for the union and build the complement of the resulting union NFA.
All these NFAs built can be converted using equivalent DFA using the subset construction algorithm.
Suffix
Problem: If M1 is a DFA that accept language L1 over an alphabet then design a finite automaton M that accepts all strings X such that X is a suffix of some string in L1.
Mathematically, L ≡ {x | yx ∈ L1 for some y}. Here ∈ implies the set-membership.
Example
A suffix is a subsequence that can begin somewhere in the given sequence and goes until the end. Note that the complete sequence is also a suffix of itself. If M1 accepts {“11”, “001”} then M should accept L1* ≡ {“11”, “001”, “1”, “01”}.
Design strategy
The string accepted by M may start anywhere in a valid string accepted by M1 => final states of M1 should remain the same and for every path leading to some final state and starting from the initial state, we add empty-transitions from the initial state to every state in such a path.
Mathematically,

Reverse
Problem: If M1 is a DFA that accept language L1 over an alphabet then design a finite automaton M that accepts all strings X such that X is revere of some string in L1.
Mathematically, L ≡ L1R ≡ {xR | x ∈ L1}. Here ∈ implies the set-membership.
Example
The reverse of a sequence is the sequence obtained by reading the given sequence in opposite direction. If M1 accepts {“11”, “001”} then M should accept L1R ≡ {“11”, “100”}.
Design strategy
The string accepted by M is the reverse of a valid string accepted by M1 => the input should start from one of the final states of M1, move in the opposite direction, and reach the initial state. Thus — make the final states as non-final; make initial state as final; reverse the direction of the arrows in every path from the old final states to the old initial state. What about the initial state in M? It should be the old final state from which the input began. But what if there are multiple final states in M1? To resolve it, we need to add a new initial state and empty-transitions from that to the old final states.
Mathematically,
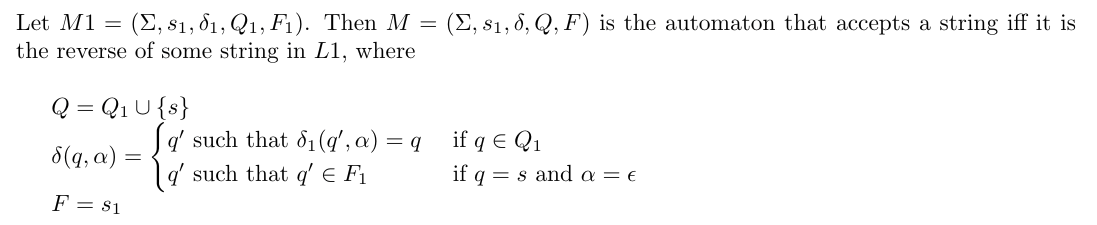
Similarly, the FA accepting the prefix of a some string in L1 can be computed by changing all the states to final, in every path that starts from the initial state and ends in some original final state . Here, L ≡ {x | xy ∈ L1 for some y}. Here ∈ implies the set-membership.
PS: On the mathematical description:
Firstly, we are assuming that the given automata are DFA. The same justification should work if those automata were NFA.
Secondly, the more rigorous mathematical standards would require us to use set notation for the transition function expressed in the mathematical descriptions (since the transition function of an NFA results in a set of states). I have been a bit lax here, aiming to capture the intuition rather than focussing on the symbolic correctness of the notations. Ideally, individual states in this expression should definitely be represented as a set. As for the expressions involving δ1 and δ2, it depends on whether M1 and M2 are NFA or DFA. In case of DFA, it should be enclosed in set-braces while δ for NFA outputs a set, so it doesn’t need the braces.
Lastly, the final set of δ(q, α) will be the union of the sets obtained from each condition that has been satisfied. For example, consider the expression of Kleene; q may satisfy both the conditions, namely, q is in Q1 and q is in F1, then δ(q, α) will be δ1(q, α) ∪ {s}. If no condition is satisfied, the result is same as an empty set. Also, we assume that if M1 (or M2) is DFA, then δ1(q,∈) (or δ2(q,∈)) is an empty set.
Epilogue:
Please pardon the verbosity, oversimplification, and baby-steps. This part of the post is also more relevant to undergraduate students. Move onto the next part .🙂
Cheers!